GREENSBORO, NC – February 7, 2022 – Qorvo® (Nasdaq:QRVO), a leading provider of innovative RF solutions that connect the world, announced it has been awarded a $4.1 million follow-on contract with the National Institutes of Health (NIH) through the Rapid Acceleration of Diagnostics (RADxSM) initiative. The contract, awarded to Qorvo Biotechnologies, a wholly owned subsidiary of Qorvo, will help advance the clinical trials and market launch of both a SARS-CoV-2/ Flu Combo Assay and SARS-CoV-2 Antigen Pooling on the Qorvo Omnia™ diagnostic test platform.
The SARS-CoV-2/Flu Combo Assay will simultaneously detect and differentiate between SARS-CoV-2, Flu A and Flu B in an all-in-one test using a single swab sample in approximately 20 minutes. The antigen pooling application will allow up to six samples to be processed together and tested at the same time. Antigen pooling enables significant time and cost savings for screening groups of people who aren’t experiencing SARS-CoV-2 symptoms. Qorvo continues to develop advanced testing formats for SARS-CoV-2 detection in response to the pandemic while focusing on test performance, workflow efficiencies and cost control for end users. Combined with a previous NIH contract award of $24.4 million, this award positions Qorvo to accelerate the production and market launch of multiple COVID testing solutions using a single platform.
Philip Chesley, president of Qorvo Biotechnologies, said, “Today’s COVID testing market is demanding high quality testing infrastructure at the point of care (POC), with automated workflow, menu expansion and scalability to serve future needs of the pandemic. This contract award and continued RADx support enable Qorvo to more effectively address the expanding requirements of diverse end use settings.”
Tiffani Bailey Lash, Ph.D., Co-Program Lead for the RADx Tech program, said, “Qorvo’s antigen test has a lot of potential with near-PCR-level accuracy for use at POC settings.”
The Qorvo Omnia platform represents an innovative diagnostic technique by using high frequency Bulk Acoustic Wave (BAW) sensors to achieve rapid SARS-CoV-2 (COVID-19) antigen test results. BAW sensor technology enables low limit of detection (LOD) levels similar to molecular testing capability.
For more information, visit www.qorvobiotech.com.
This project has been funded in whole or in part with Federal funds from the National Institute of Biomedical Imaging and Bioengineering, National Institutes of Health, Department of Health and Human Services, under Contract No 75N92021C00008.
The Qorvo Omnia SARS-CoV-2 Antigen Test was granted emergency use authorization (EUA) from the U.S. Food and Drug Administration (FDA) in April 2021. The test is authorized for the qualitative detection of nucleocapsid viral antigens from SARS-CoV-2 in nasal swab specimens from individuals who are suspected of having COVID-19 by their healthcare provider within the first 6 days of symptom onset. The Qorvo Omnia SARS-CoV-2 Antigen Test has not been FDA cleared or approved. It has been authorized by the FDA under an Emergency Use Authorization and testing is limited to laboratories certified under the Clinical Laboratory Improvement Amendments of 1988 (CLIA), 42 U.S.C. §263a, to perform moderate or high complexity tests. This test has been authorized only for the detection of proteins from SARS-CoV-2, not for any other viruses or pathogens. These tests are only authorized for the duration of the declaration that circumstances exist justifying the authorization of emergency use of in vitro diagnostic tests for detection and/or diagnosis of COVID-19 under Section 564(b)(1) of the Act, 21 U.S.C. § 360bbb-3(b)(1), unless the authorization is terminated or revoked sooner.
About Qorvo Biotechnologies
Qorvo Biotechnologies, LLC is a wholly owned subsidiary of Qorvo, Inc. focused on the development of point-of-care (POC) diagnostics solutions leveraging Qorvo’s innovative BAW sensor technology.
About Qorvo
Qorvo (Nasdaq: QRVO) makes a better world possible by providing innovative Radio Frequency (RF) solutions at the center of connectivity. We combine product and technology leadership, systems-level expertise and global manufacturing scale to quickly solve our customers’ most complex technical challenges. Qorvo serves diverse high-growth segments of large global markets, including advanced wireless devices, wired and wireless networks and defense radar and communications. We also leverage unique competitive strengths to advance 5G networks, cloud computing, the Internet of Things, and other emerging applications that expand the global framework interconnecting people, places and things. Visit www.qorvo.com to learn how Qorvo connects the world.
Qorvo is a registered trademark of Qorvo, Inc. in the U.S. and in other countries. All other trademarks are the property of their respective owners.
| Media Contact: Brent Dietz Qorvo Director of Corporate Communications +1 336-678-7935 [email protected] |
This press release includes “forward-looking statements” within the meaning of the safe harbor provisions of the Private Securities Litigation Reform Act of 1995. These forward-looking statements include, but are not limited to, statements about our plans, objectives, representations and contentions, and are not historical facts and typically are identified by use of terms such as “may,” “will,” “should,” “could,” “expect,” “plan,” “anticipate,” “believe,” “estimate,” “predict,” “potential,” “continue” and similar words, although some forward-looking statements are expressed differently. You should be aware that the forward-looking statements included herein represent management’s current judgment and expectations, but our actual results, events and performance could differ materially from those expressed or implied by forward-looking statements. We do not intend to update any of these forward-looking statements or publicly announce the results of any revisions to these forward-looking statements, other than as is required under U.S. federal securities laws. Our business is subject to numerous risks and uncertainties, including those relating to fluctuations in our operating results; our substantial dependence on developing new products and achieving design wins; our dependence on several large customers for a substantial portion of our revenue; the COVID-19 pandemic materially and adversely affecting our financial condition and results of operations; a loss of revenue if defense and aerospace contracts are canceled or delayed; our dependence on third parties; risks related to sales through distributors; risks associated with the operation of our manufacturing facilities; business disruptions; poor manufacturing yields; increased inventory risks and costs due to timing of customer forecasts; our inability to effectively manage or maintain evolving relationships with platform providers; our ability to continue to innovate in a very competitive industry; underutilization of manufacturing facilities as a result of industry overcapacity; unfavorable changes in interest rates, pricing of certain precious metals, utility rates and foreign currency exchange rates; our acquisitions and other strategic investments failing to achieve financial or strategic objectives; our ability to attract, retain and motivate key employees; warranty claims, product recalls and product liability; changes in our effective tax rate; changes in the favorable tax status of certain of our subsidiaries; enactment of international or domestic tax legislation, or changes in regulatory guidance; risks associated with environmental, health and safety regulations and climate change; risks from international sales and operations; economic regulation in China; changes in government trade policies, including imposition of tariffs and export restrictions; we may not be able to generate sufficient cash to service all of our debt; restrictions imposed by the agreements governing our debt; our reliance on our intellectual property portfolio; claims of infringement of third-party intellectual property rights; security breaches and other similar disruptions compromising our information; theft, loss or misuse of personal data by or about our employees, customers or third parties; provisions in our governing documents and Delaware law may discourage takeovers and business combinations that our stockholders might consider to be in their best interests; and volatility in the price of our common stock. These and other risks and uncertainties, which are described in more detail in Qorvo’s most recent Annual Report on Form 10-K and in other reports and statements filed with the Securities and Exchange Commission, could cause actual results and developments to be materially different from those expressed or implied by any of these forward-looking statements.

Original blog post from: https://www.qorvo.com/design-hub/blog/boosting-bandwidth-to-future-proof-catv-solutions
Future entertainment systems and work-at-home environments are rapidly moving toward greater two-way interaction, which calls for enhanced downstream bandwidth and upstream capabilities. To stay competitive in the evolving CATV business, innovative technologies are needed to keep up with demands. One component that can play a vital role in this evolution is the CATV amplifier based on gallium nitride (GaN) technology. This post provides insight into how to do just that. The following is an excerpt from a Qorvo white paper, How to Increase Downstream Bandwidth and Upstream Capabilities in CATV Amplifiers with Greater Efficiency.
Meeting Higher Uplink Bandwidth Demands
Typical allocations for upstream traffic on Hybrid Fiber Coax (HFC) networks in the US range from 5 MHz to 42 MHz. User activities and new use cases are driving the need for increased capacity. In response, some multiple system operators (MSOs) are setting mid-splits or high-splits within the available bandwidth to accommodate these demands, reducing downstream bandwidth and possibly curtailing content or services.
MSOs facing this challenge are exploring the options available through DOCSIS 3.1 or DOCSIS 4.0 specifications. Upstream capacity within DOCSIS 3.1 can be extended up to 204MHz. While DOCSIS 4.0 allows the upstream to go up to 684MHz in both full duplex (FDX) and extended spectrum DOCSIS (ESD). Figure 1 shows how full duplex (FDX) let upstream and downstream traffic share the 684 MHz frequency range.


Figure 1. DOCSIS 4.0 FDX spectrum for upstream (US) and downstream (DS).
Maintaining Linearity
The trend toward extended CATV bandwidth has led engineers and system architects to explore new technologies as networks are upgraded, requiring a newer generation of passive and active products. To meet demands for the increased bandwidth and data rates, CATV amplifiers must maintain a higher linear output power.
Gallium Nitride (GaN) devices can deliver more than the necessary efficiency and performance to satisfy DOCSIS requirements for CATV amplifiers. Consistent linearity is a primary requirement for reliable data transmission and signal integrity across HFC networks. The nonlinear behavior of active power devices can degrade the signal quality, leading to bit errors on digital channels and sometimes complete failure when trying to demodulate the signal.
Linearity of a gain block or amplifier depends primarily on these factors:
- Semiconductor technology
- Circuit design
- Power consumption
- Thermal design
A high degree of linearity and efficiency are paramount when designing an HFC amplifier, and this is where GaN-based components have a clear advantage. Figure 2 shows the fundamental components of a CATV amplifier. In terms of linear output, the downstream performance of an HFC amplifier or node largely relies on the output stage gain block (also called the power doubler).
What is DOCSIS?
Data Over Cable Service Interface Specification (DOCSIS) is an international telecommunications standard that permits the addition of high-bandwidth data transfer to an existing cable television (CATV) system. It is used by many cable television operators to provide Internet access over their existing hybrid fiber-coaxial (HFC) infrastructure. The version numbers are sometimes prefixed with simply “D” instead of “DOCSIS” (e.g., D3 for DOCSIS 3).
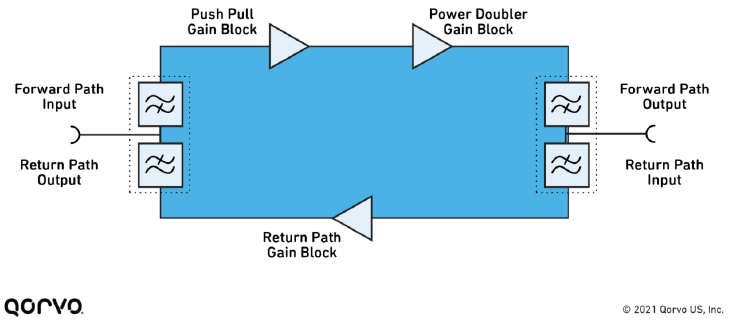
Figure 2. Block diagram of a CATV amplifier.
GaN represents an enabling technology for power amplifier designs that can accommodate the demands of the DOCSIS 3.1 and DOCSIS 4.0 standards. Figure 3 illustrates a design stage that originally implemented the gain block architecture using field-effect transistors (FETs) based on GaAs technology. Replacing FET3 and FET4 with GaN-based components results in a substantial performance improvement because of the characteristics of these devices, including operation at high frequencies, high-voltage ruggedness, high current density, and power handling. GaN supports up to 10 W/mm compared to 1 W/mm for GaAs.
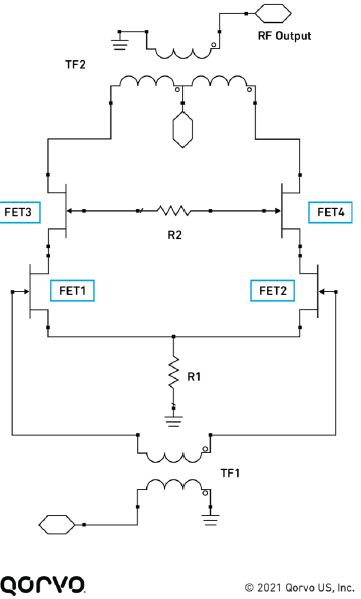
Figure 3. Gain block architecture improved through the use of GaN-based FETs.
Comparing the relative characteristics of material technologies used in CATV gain-block architecture, Figure 4 shows the advantages of GaN technology, enabling MSOs to boost linear output while maintaining existing amplifier spacing. This can minimize upgrade costs and make it possible to implement fiber deep solutions, locating fiber closer to the customer to enhance service and at the same time reducing or eliminating amplifiers.
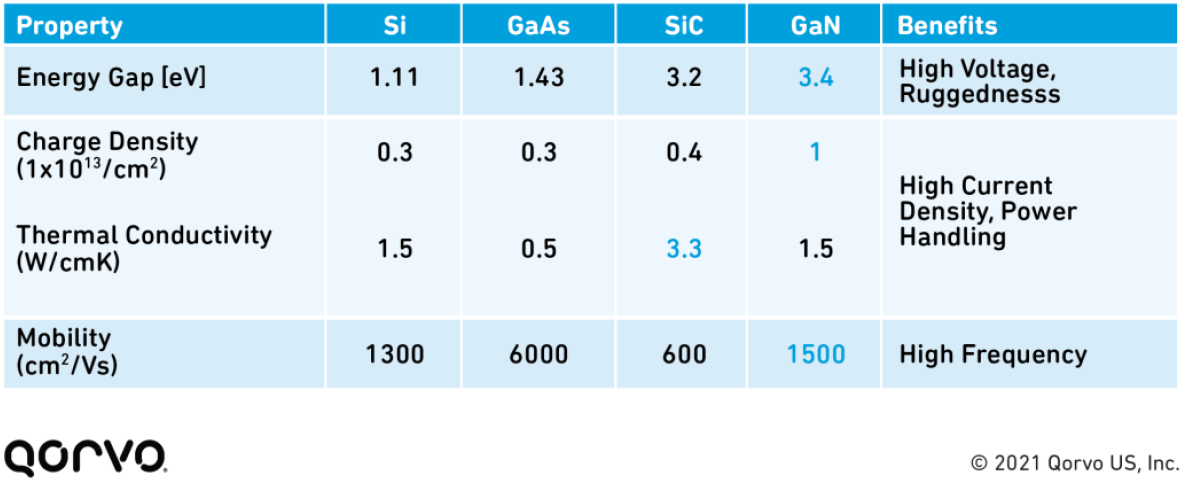
Figure 4. Characteristics of GaN-based components compared to other options.
Qorvo Expertise in CATV Gain Blocks
Two Qorvo products are outstanding design choices in this sector:
- QPA3260 power doubler hybrid – Delivers the highest linear output up to 1.2 GHz
- QPA3315 power doubler hybrid – Supports DOCSIS 4.0 implementations in designs requiring up to 1.8 GHz capabilities
With the need for greater downstream bandwidth and increased upstream capacities spurred by DOCSIS 3.1 and DOCSIS4.0 standards, Qorvo can help MSOs respond to the challenge with GaN-based gain blocks for CATV signal amplification. CATV equipment manufacturers can rely on proven solutions that deliver better data transport using durable and reliable components.
Have another topic that you would like Qorvo experts to cover? Email your suggestions to the Qorvo Blog team and it could be featured in an upcoming post. Please include your contact information in the body of the email.

Original blog post: https://www.qorvo.com/design-hub/blog/lights-camera-action-uwb-is-the-star-supporter-in-le-premier-royaume
With all the potential use cases for ultra-wideband (UWB) technology, it’s not surprising that it’s often found in the most unexpected places. Case-in-point: the Puy du Fou theme park in France. A recent article in blooloop outlines how UWB rescued its show “Le Premier Royaume” (“The First Kingdom”), a multi-sensory walkthrough experience set in fifth-century France, in which guests journey through the history and legend of the Frankish King Clovis.
According to the article, “During the experience, five hundred theater goers move through the sets, as eight actors execute perfectly timed entrances and exits. This is supported by lights, sound, and special effects.” The show cycles for seven hours a day, using 14 different sets throughout roughly 24,000 square feet on two levels. The challenge for the show producers was to keep pace with the visitors moving through the spaces and timing the activation of the show’s effects.
That’s where UWB came in. Puy du Fou turned to Eliko’s UWB RTLS system, which integrates Qorvo’s UWB devices and can track hundreds of objects in real-time.
Here we explore why UWB technology is conducive for precision-dependent use cases.

Eliko’s UWB RTLS system integrates Qorvo’s UWB devices and can track hundreds of objects in real-time.
UWB: Solving the ‘Where’
In show business, timing is everything. Especially for the Le Premier Royaume performance. What’s also critical for the show’s success is the ‘where.’ The timing of the lighting, special effects, actors are all based on where the audience is located in relation to its location within the theater. We have many technologies—BLE, Wi-Fi, RFID, etc.—and apps built into so many of our devices that accurately track the ‘when’ and inform us of ‘what.’ But they’re not designed to track the ‘where,’ the precise location in real-time—second by second. However, this is exactly what ultra-wideband does.
With UWB, the show’s production could synch all the devices so the apps always know precisely where things are—down to the centimeter and the second. Being a low-power, ultra-wide bandwidth radio technology, UWB offers characteristics that make it ideal for use cases such as Puy du Fou’s—the most important in this case are precision ranging, precise location, and fast data communication.
Why UWB?
To better understand why UWB, in particular, is the most conducive for applications like Puy du Fou’s – a challenging environment for RF technologies – let’s take a look at how it compares to other technologies like BLE and Wi-Fi. This table shows that UWB has all the ingredients to overcome the show’s challenges.

A scene from “Le Premier Royaume” (“The First Kingdom”), a multi-sensory walkthrough experience set in fifth-century France.
| UWB | Bluetooth® Low Energy | Wi-Fi | |
| Accuracy | Centimeter | 1-5 meters | 5-15 meters |
| Reliability | Strong immunity to multi-path and interference | Very sensitive to multi-path, obstruction and interference | Very sensitive to multi-path, obstruction and interference |
| Range/coverage | Typ. 70m Max 250m |
Typ. 15m Max 100m |
Typ. 50m Max 150m |
| Data Communications | Up to 27 Mbps | Up to 2 Mbps | Up to 1 Gbps |
What sets UWB apart the most from the other technologies is its accuracy. Like other location technologies, UWB doesn’t rely on satellites for communication. Instead, devices containing UWB technology (like antennas on the show’s actors, lighting, cameras, etc.) communicate directly with each other to determine location and distance. What’s different about UWB from the others is this accuracy is achieved by measuring the time that it takes signal pulses to travel between devices, which can be calculated based on the time-of-flight of each transmitted pulse.
The accuracy of this method depends on the signal’s bandwidth; very wide signals are needed to achieve high accuracy. UWB signals use roughly 500 MHz of bandwidth—many times wider than other technologies sometimes used for location sensing. That enables UWB to achieve centimeter precision, which is critical for many applications.
UWB technology also works in non-line-of-sight conditions where the use of cameras to track location is not possible. This means that the signal is capable of going through obstructions like the sets while maintaining a very high location accuracy. In addition, as it operates at frequencies between 6 and 8GHz, it has no interference issues with other radio waves.
For more in-depth information about how UWB technology works, read the whitepaper, Getting Back to Basics with Ultra-Wideband (UWB).
Check Out Other UWB Use Cases
UWB is an old radio technology enabling new opportunities for rich real-time applications. Companies and application developers are already enabling new UWB-based services that benefit both businesses and individuals. But they are only scratching the surface. There are many use cases where UWB can create an experience and enrich our personal lives. For more ideas on use cases, watch this video. You can also read about how UWB is used at the Museum of the Bible to enhance the visitor experience, as well as how Volkswagen is optimizing its production by integrating UWB into its operations.
The Bluetooth® word mark and logos are registered trademarks owned by Bluetooth SIG, Inc. and any use of such marks by Qorvo US, Inc. is under license. Other trademarks and trade names are those of their respective owners.

Original blog post: https://ams.com/sensor-blog/1d-tof-family
ams 1D time-of-flight ranging sensor family offers mobile and industrial customers the right combination of performance, size, and cost to meet their needs.
When innovating sensor technology for a better lifestyle, ams engineers are balancing three attributes that are vital to customers: sensor performance, sensor size, and system cost. These variables are almost infinitely adjustable according to our customers’ evolving needs and specifications, competitive conditions, regulatory constraints or bill of materials requirements. How we design our product portfolio is based on our reading of the market and what our customers and close design partners tell us they want.
Customers are in a never-ending race to deliver better products and experiences. And as part of this, 1D Time-of-Flight sensors for front and world-facing applications are becoming increasingly important in the mobile, consumer, wearables, PC and industrial segments. The ams family of 1D ToF ranging sensors, developed for Laser Distance Auto-Focus (LDAF) applications within the mobile phone industry area also bringing benefit and increasingly winning in applications including PC user detection enabling auto lock/unlock, obstacle avoidance in robotic vacuum cleaners, inventory management, to name a few.
Broadening the family of time-of-flight (ToF) ranging sensors
ams has a strong history in bringing 1D ToF sensing innovations to market. Our most recent innovations include the world’s smallest 1D ToF sensor for accurate proximity sensing and distance measurement in smartphones’ – the TMF8701 and the TMF8801 which extends the operating range of the direct time of flight module to enable smartphones with space-saving accurate distance measurement. Now, ams brings rounds out the TMF sensor family with the TMF8805 adjusting the performance/cost variables to give customers greater flexibility and choice, especially for applications and products with massive growth potential or competing in the uncertainty of emerging markets.
TMF8805 – for mobile phone camera applications and more
The TMF8805 is a highly-integrated module which includes a class 1 eye-safe 940nm Vertical Cavity Surface Emitting Laser (VCSEL), Single Photon Avalanche Diode (SPAD) array, time-to-digital converter (TDC) along with a low power, high performance microcontroller. This system-in-module integration enables robust and precise distance measurements in the 20mm and 2500mm range, all packaged in the industry’s smallest footprint measuring only 2.2mm x 3.6mm x 1.0mm.
This high precision distance measurement is ideal for use in world-facing, LDAF mobile phone applications by enabling a fast, high-precision auto-focus feature. The new sensor joins the existing TMF8801 and TMF8701 time-of-flight sensors from ams, providing products which meet a range of cost and performance requirements across the mobile, wearable and consumer electronics, computing and industrial markets.
To meet evolving expectations in a transforming world, customers come to ams for our simple-to-integrate, plug-and-play sophisticated sensor systems, while often benefiting from the ‘speed premium’ of our supplier ecosystem and specialist expertise. The TMF8805 time-of-flight sensor is now in mass production and an evaluation kit featuring the TMF8805 along with a comprehensive evaluation GUI is also available.
Blog post from: https://www.knowles.com/about-knowles/blog/challenges-5g-brings-to-rf-filtering
In the race to implement mainstream 5G wireless communication, the world is waiting to see if this next-generation network will achieve a hundredfold increase in user data rates. This transformative technology not only boosts performance for the latest cell phones, but also for fixed wireless access (FWA) networks and Internet of Things (IoT) smart devices. In order to reach 10 Gbps peak data rates, the increase in channel capacity must come from somewhere. A key innovation at the heart of 5G is utilizing new frequencies greater than 20 GHz in the millimeter wave (mmWave) spectrum, which offers the most dramatic increase in available bandwidth.
A well-known downside to high frequencies is the range limitation and path loss that occurs through air, objects, and buildings. The key workaround for mmWave base station systems is the use of multi-element beamforming antenna arrays in both urban and suburban environments. Since mmWave signals require much smaller antennas, they can be tightly packed together to create a single, narrowly focused beam for point-to-point communication with greater reach.

In order to overcome the range limitations of mmWave frequencies, dense arrays of antennas are used to create a tightly focused beam for point-to-point communication.
Changes in Radio Architecture for mmWave Beamforming
Of course, these new beamforming radio architectures bring a whole new set of challenges for designers. Traditional filtering solutions for radios operating in the ranges of 700 MHz and 2.6 GHz are no longer suitable for mmWave frequencies such as 28 GHz. For example, cavity filters are often used in the RF front ends of LTE macrocells. However, an inter-element spacing of less than half the wavelength (λ/2) is required to avoid the generation of grating lobes in antenna array systems. This inter-element spacing is about 21.4 cm at 700 MHz frequency versus only about 5 mm at 28 GHz. Such a requirement therefore calls for very small form factor components in the array. Not only will the whole RF front end be reduced in size, but also the number of RF paths will be increased – which means the filters right next to the antennas must be very compact.
 As the frequency increases, the antenna size must decrease, leading to significant changes in the mmWave beamforming radio architecture.
As the frequency increases, the antenna size must decrease, leading to significant changes in the mmWave beamforming radio architecture.
Addressing Challenges with mmWave Filtering
Based on decades of experience working with mmWave filtering solutions, Knowles Precision Devices has a product line of mmWave filters solutions that addresses these challenges. Using specialized topologies and material formulations, we’ve created off-the-shelf catalog designs available up to 42 GHz that are 20 times smaller than the current alternatives.

Compared to current alternatives, Knowles Precision Devices offers filter solutions that are 20 times smaller to meet mmWave inter-element spacing requirements.
As manufacturers push to increase available bandwidth, temperature stability also becomes more and more of an issue. MmWave antenna arrays may be deployed in exposed environments with extreme temperatures, and heat dissipation issues may arise from packing miniature components onto densely populated boards. In order to guarantee consistent performance, our filters are rated for stable operation from -55°C to +125°C. For example, the bandpass filters below shifted only by 140 MHz when tested over that temperature range.

The temperature response of a Knowles 18 GHz band pass filter (BPF) on CF dielectric shows little variation in performance from -55°C to +125°C.
Finally, high performance with high repeatability is key to ensuring the best spectral efficiency and rejection possible. High frequency circuits are especially sensitive to variations in performance, so precise manufacturing techniques ensure that our filter specifications – such as 3 GHz bandwidth and greater than 50 dB rejection – are properly maintained from part to part. Plus, unlike chip and wire filter solutions, our surface mount filters standardize the form factor, reduce overall assembly time, and do not require tuning – thus saving in overall labor costs and lead times.

The performance of Knowles Precision Devices 37-40 GHz BPFs shows highly repeatable performance over 100 samples, even without post-assembly tuning.
Blog post from our partner: Qorvo
https://www.qorvo.com/design-hub/blog/wifi-5-point-2-ghz-rf-filters
As engineers, we’re always looking for the simplest solution to complex system design challenges. Look no further for solutions in the 5.2 GHz Wi-Fi realm. Here we step you through the resolutions to reduce design complexity, while meeting those tough final product compliance requirements.
An Essential Part of The Wi-Fi Tri-Band System
– 5.2 GHz RF Filters
Most individuals using Wi-Fi in any setting – home, office, or coffee shop – expect a fast upload and download experience. To achieve this, individuals and businesses must move toward a tri-band radio product solution. Anyone familiar with the two Wi-Fi bands of 2.4 GHz and 5 GHz, know the higher 5 GHz band is faster for upload and download speeds. However, the use of higher frequency bands comes at a price of signal attenuation. They also have a high probability of interference with other closely aligned spectrum.
This is where Qorvo filter technology comes in. Qorvo filters help mitigate these probable interferences. In this blog, we focus on the 5.2 GHz filter technology, the higher area of the Wi-Fi tri-band. This filter technology improves the mesh network quality-of-service and helps meet system regulatory requirements.
Wi-Fi and Cellular Frequency Bands
The 5 GHz band provides over six times more bandwidth than 2.4 GHz. This is a big plus for today’s video streaming, chatting, and gaming, which is in high demand. As shown in the figure below, spectrum re-farming and the crowding of wireless standards has increased. As Wi-Fi evolves into even higher realms of 5 GHz and 6 GHz, the crowding continues. As seen in the below figure, the 5 GHz unlicensed area clearly must coexist with cellular frequencies on all sides. One such area is the 5.2 GHz band.

Figure 1: Major wireless frequency bands for 5G Frequency Range (FR) 1 & 2
The Wi-Fi 5.2 GHz Space
The Wi-Fi 5 GHz UNII (Unlicensed National Information Infrastructure) arena is primarily used in routers in retail, service providers and enterprise spaces. These routers are commonly found in mesh networks, extenders, gateways and outdoor access points. In the UNII1-2a band (i.e. 5150-5350 MHz – 5.2 GHz band), maintaining a minimum RF system pathloss is important. Providing a minimum filter insertion loss is imperative to reduce power consumption, achieve better signal reception, and decrease thermal stress. This helps system designers to deliver low carbon footprint end-products. Additionally, for the 5.2 GHz band, a high out-of-band filter rejection is desired – notably around 50 dB or greater at 5490-5850 MHz – which helps mitigate crosstalk and enables coexistence with the 5.6 GHz UNII band, as shown in Figure 2 below.
5.2 GHz Filter Deep-Dive Analysis (QPQ1903)
To meet the need of the true mesh tri-band application, a well-designed filter is required. Today, few filter suppliers can meet the standard’s body specifications of rejection, insertion loss and power handling in the 5.2 GHz band. As shown in the below figure, Qorvo provides several filter solutions for the UNII 5 GHz bands.

Figure 2: 5 GHz UNII frequency bands, bandwidths, bandedge parameters, and filters
A Review of The Wi-Fi Standard Specifications
High Rejection – A high rejection is critical in a system for two main reasons – one being the need to mitigate interference, and two, to mitigate unwanted signal noise. Therefore, customers and standards bodies have set a desired high parameter of 50 dB or greater on rejection rate for critical out-of-band signals. But it is important to achieve this without losing the integrity of the RF signal range and capacity. Using Qorvo bandBoost™ filters such as the QPQ1903 achieves this goal.
Learn More about Qorvo’s bandBoost™ filters:
As noted in Figure 2 above, coexistence with the Wi-Fi 5.6 GHz band has only a 120 MHz gap. Meeting the 50 dB or greater rejection at this frequency (5490-5850 MHz) within this small gap is challenging. It requires filter technologies with steep out-of-band skirts and a high rejection rate. BAW (bulk acoustic wave) SMR (solidly mounted resonator) technology is well suited to meet thermal and high rejection filter requirements. BAW-SMR has a vertical heat flux acoustic reflector that allows thermal heat to dissipate away quickly and efficiently from the filter. BAW exhibits very little frequency shifts due to self-heating as the topology of BAW-SMR provides a lower resistance, preventing the resonators from overheating. As shown in Figure 3 below, the rejection rate of the 120 MHz gap is greater than 50 dB, well within the regulatory guidance parameters.

Figure 3: 5.2 GHz QPQ1903 performance measurements @ 25⁰C
Insertion Loss – In Figure 3 above, the insertion loss performance data for the 5.2 GHz bandBoost™ filter, QPQ1903, is 1.5 dB or better. Thus, providing improved system pathloss and power consumption. This translates directly to increased coverage range, better reception of the signal and simplified thermal management of the end product. Additionally, the return loss (not shown) meets the required specification by 2 dB or better across the entire pass band. This allows for an easier system match when using a discrete 5.2 GHz filter solution, which is especially critical in high linearity Wi-Fi 6 systems.
Power Handling – Power handling has become a major requirement for today’s wireless systems. 5G and the increases in RF input power levels to the receiver have attributed heavily to this new high-power handling system requirement. Thus, RF filters must be able to meet higher input power levels, sometimes up to 33 dBm. Luckily due to BAW-SMR’s ability to dissipate heat efficiently, it can easily attain this goal without compromising performance.
Not only has Qorvo BAW technology met the required critical regulatory specifications, but in most cases has done so with additional margin, and in the higher temperature ranges of up to 95⁰C – further helping customers and system designers meet stringent final product thermal management requirements.
New Wi-Fi System Complexity Challenges
The onset of Wi-Fi 6 and 6E standards has introduced additional application and system design complexity. Some of the most common challenges are:
- Tri-band Wi-Fi
- Smaller, sleeker device form factors
- Higher temperature conditions due to form factor and application area requirements
- Completely integrated solutions with no external tuning
Tri-band Wi-Fi – The need for data capacity and coverage has led to an explosion of the tri-band architecture of 2.4 GHz, 5.2 GHz and 5.6 GHz bands in gateways and end-nodes, as shown in Figure 4 below. It allows users to connect more devices to the internet using the 5 GHz spectrum in a more efficient way. For example, if you’re using a home mesh system with multiple routers to cover a larger space, the second 5.6 GHz band acts as a dedicated communications line between the two routers to speed up the entire system by as much as 180% over dual-band configurations.

Figure 4: 5.2 GHz & 5.6 GHz Wi-Fi filter response bandwidths and bandedge parameters
Higher temperature conditions – New gateway designs require smaller form factors, sometimes half the size of previous product versions, with a higher number of RF antenna pathways (a tri-band router can have upwards of 8 RF pathways). Because of the confined space and increased number of antenna pathways, system thermal management becomes even more challenging. There are also gateway applications with higher temperatures at the extremes of -20⁰C to +95⁰C for outside environments.
Smaller form factor & integration – Today’s gateway devices are sleeker, stylish and have smaller form factors. The demand for smaller gateway form factors is pushing Wi-Fi integrated circuits to shrink as well. Additionally, this is moving semiconductor technologies toward creating smaller and thinner devices to mitigate system designer costs.
To accommodate this initiative, Qorvo has also integrated its filter technology into complete RF front-end designs to help system designers reduce design time, meet smaller size requirements, and increase time-to-market.

Figure 5: Comparison of 5 GHz ceramic versus Qorvo QPQ1903 BAW filters
As system designers continue to meet higher frequency demand initiatives – brought on by the hunger for more frequency spectrum – design challenges increase. New hurdles like system pathloss, signal attenuation, designs in higher frequency realms and meeting coexistence standards are becoming more prevalent. Qorvo has worked extensively with network standards bodies and customers across the globe to ensure their designs meet all compliance needs. We work hard to provide products that meet these highly sought-after specifications with additional margin. This proactive work ultimately allows our customers to concentrate on delivering best-in-class products rather than trying to mitigate difficult design and certification issues.
Have another topic that you would like Qorvo experts to cover? Email your suggestions to the Qorvo Blog team and it could be featured in an upcoming post. Please include your contact information in the body of the email.

A Beginner’s Guide to Segmentation in Satellite Images: Walking through machine learning techniques for image segmentation and applying them to satellite imagery
Blog from: https://www.gsitechnology.com/
In my first blog, I walked through the process of acquiring and doing basic change analysis on satellite data. In this post, I’ll be discussing image segmentation techniques for satellite data and using a pre-trained neural network from the SpaceNet 6 challenge to test an implementation out myself.
What is image segmentation?
As opposed to image classification, in which an entire image is classified according to a label, image segmentation involves detecting and classifying individual objects within the image. Additionally, segmentation differs from object detection in that it works at the pixel level to determine the contours of objects within an image.
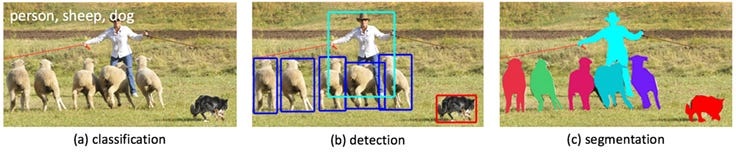
In the case of satellite imagery, these objects may be buildings, roads, cars, or trees, for example. Applications of this type of aerial imagery labeling are widespread, from analyzing traffic to monitoring environmental changes taking place due to global warming.

The SpaceNet project’s SpaceNet 6 challenge, which ran from March through May 2020, was centered on using machine learning techniques to extract building footprints from satellite images—a fairly straightforward problem statement for an image segmentation task. Given this, the challenge provides us with a good starting point from which we can begin to build understanding of what is an inherently advanced process.
I’ll be exploring approaches taken to the SpaceNet 6 challenge later in the post, but first, let’s explore a few of the fundamental building blocks of machine learning techniques for image segmentation to uncover how code can be used to detect objects in this way.
Convolutional Neural Networks (CNNs)
You’re likely familiar with CNNs and their association with computer vision tasks, particularly with image classification. Let’s take a look at how CNNs work for classification before getting into the more complex task of segmentation.
As you may know, CNNs work by sliding (i.e. convolving) rectangular “filters” over an image. Each filter has different weights and thus gets trained to recognize a particular feature of an image. The more filters a network has—or the deeper a network is—the more features it can extract from an image and thus the more complex patterns it can learn for the purpose of informing its final classification decision. However, given that each filter is represented by a set of weights to be learned, having lots of filters of the same size as the original input image makes training a model quite computationally expensive. It’s largely for this reason that filters typically decrease in size over the course of a network, while also increasing in number such that fine-grained features can be learned. Below is an example of what the architecture for an image classification task might look like:
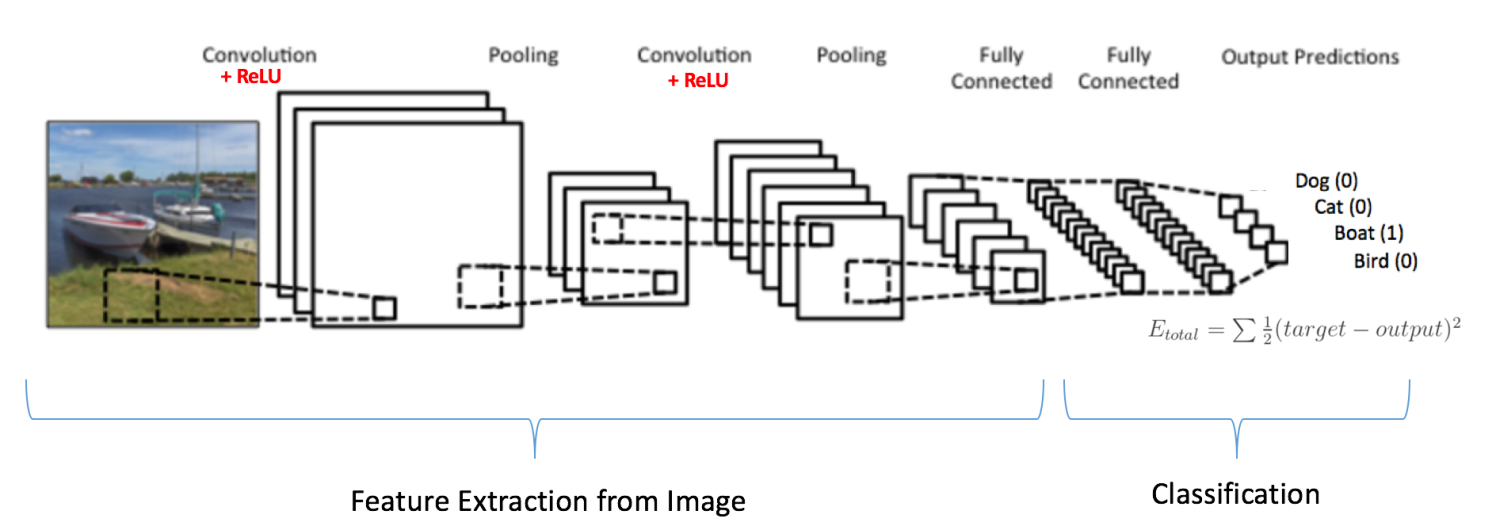
As we can see, the output of the network is a single prediction for a class label, but what would the output be for a segmentation task, in which an image may contain objects of multiple classes in different locations? Well, in such a case, we want our network to produce a pixel-wise map of classifications like the following:
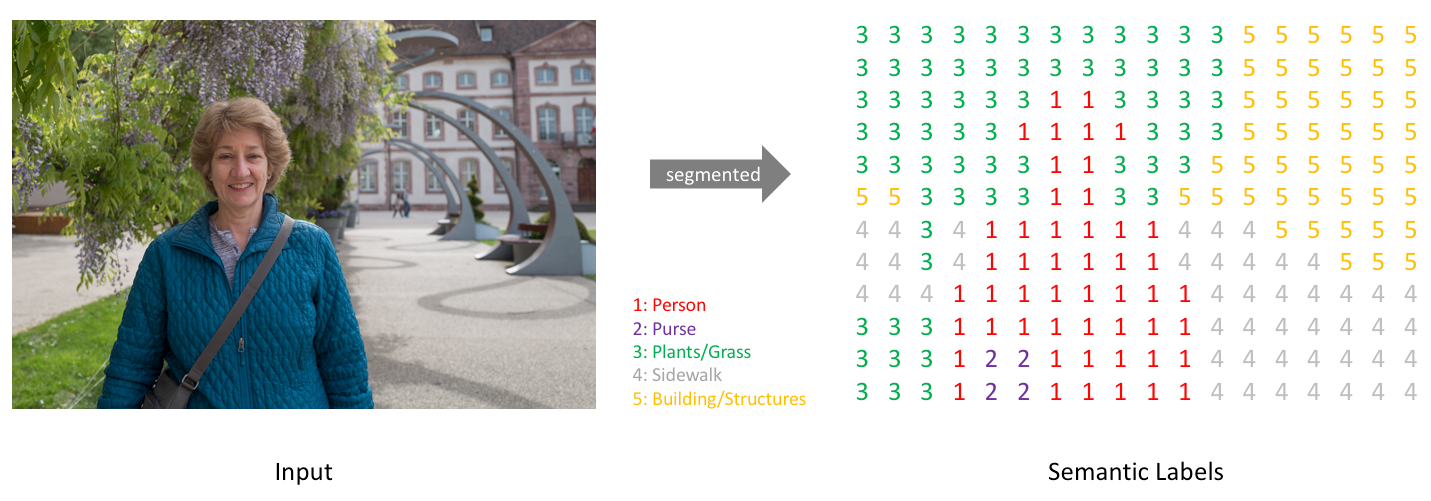
An image and its corresponding simplified segmentation map of pixel class labels. Source
To generate this, our network has a one-hot-encoded output channel for each of the possible class labels:

These maps are then collapsed into one by taking the argmax at each pixel position.
The tricky part of achieving this segmentation is that the output has to be aligned with the input image—we can’t follow the exact same downsampling architecture that we use in a classification task to promote computational efficiency because the size and locality of the class areas must be preserved. The network also needs to be sufficiently deep to learn detailed enough representations of each of the classes such that it can distinguish between them. One of the most popular kinds of architecture for meeting these demands is what is known as a Fully Convolutional Network.
Fully Convolutional Networks (FCNs)
FCN’s get their name from the fact that they contain no fully-connected layers, that is, they are fully convolutional. This structure was first proposed by Long et al. in a 2014 paper, which I aim to summarize key points of here.
With standard CNNs, such as those used in image classification, the first layer of the network is fully-connected, meaning it has the same dimensions as the input image; this means that the size of the first layer must be fixed to align with the input image. Not only does this render the network inflexible to inputs of different sizes, it also means that the network uses global information (i.e. information from the entire image) to make its classification decision, which does not make sense in the context of image segmentation in which our goal is to assign different class labels to different regions of the image. Convolutional layers, on the other hand, are smaller than the input image so that they can slide over it—they operate on local input regions.
In short, FCNs replace the fully-connected layers of standard CNNs with convolutional layers with large receptive fields. The following figure illustrates this process. We see how a standard CNN for classification of a cat-only image can be transformed to output a heatmap for localizing the cat in the context of a larger image:
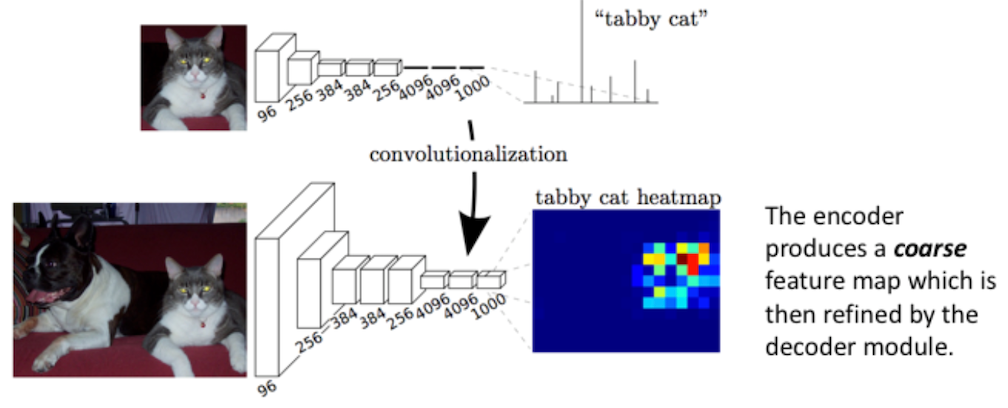
Moving through the network, we can see that the size of the layers getting smaller and smaller for the sake of learning finer features in a computationally efficient manner—a process known as “downsampling.” Additionally, we notice that the cat heatmap is of coarser resolution than the input image. Given these factors, how does the coarse feature map get translated back to the size of the input image at a high enough resolution such that the pixel classifications are meaningful? Long et al. used what is known as learned upsampling to expand the feature map back to the same size as the input image and a process they refer to as “skip layer fusion” to increase its resolution. Let’s take a closer look at these techniques.
Demystifying Learnable Upsampling
Prior approaches to upsampling relied on hard-coded interpolation methods, but Long et al. proposed a technique that uses transpose convolution to upsample small feature maps in a learnable way. Recall the way that normal convolution works:
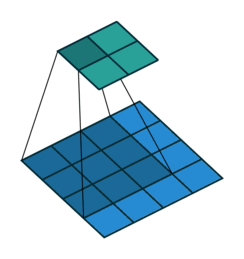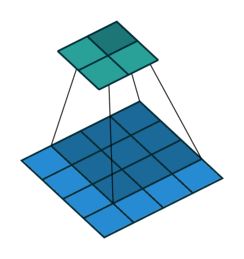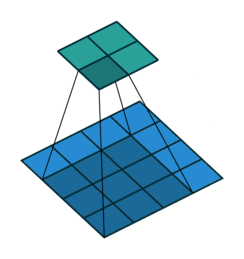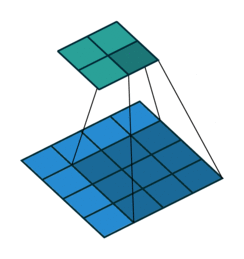
The filter represented by the shaded area slides over the blue input feature map, computing dot products at each position to be recorded in the green output feature map. The weights of the filter are what is being learned by the network during training.
Transpose convolution works differently: the filter’s weights are all multiplied by the scalar value of the input pixel it is positioned over, and these values get projected to the output feature map. Where filter projections in the output map overlap, their values are added.
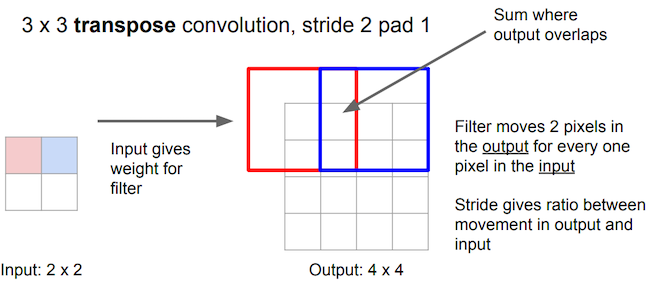
Long et al. use this technique to upsample the feature map rendered by network’s downsampling layers in order to translate its coarse output back to pixels that align with those of the input image, such that the network’s architecture looks like this:
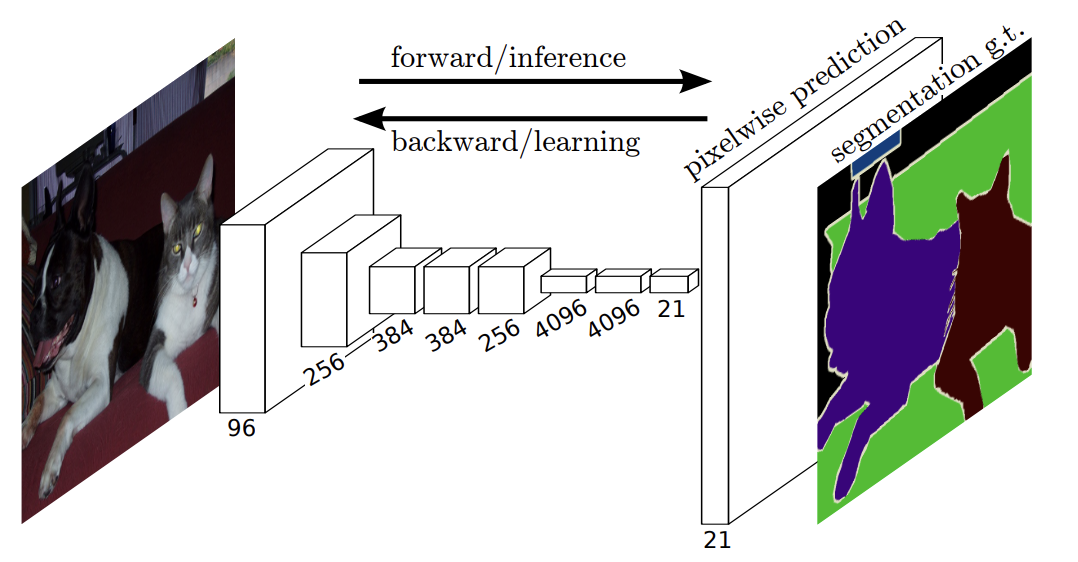
An example of a final upsampling layer appended to the downsampling path to render a full-sized segmentation map. Note that the final feature map has 21 channels, representing the number of classes for the particular segmentation challenge being explored in the paper. Source
However, simply adding one of these transpose convolutional layers at the end of the downsampling layers yields spatially imprecise results, as the large stride required to make the output size match the input’s (32 pixels, in this case) limits the scale of detail the upsampling can achieve:
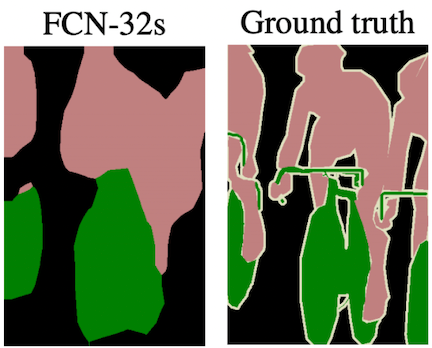
The upsampled segmentation map (left) is appropriately scaled to the input image but lacks spatial precision. Source
Luckily, this lack of spatial precision can be somewhat mitigated by “fusing” information from layers with different strides, as we’ll now discuss.
Skip Layer Fusion
As previously mentioned, a network must be deep enough to learn detailed features such that it can make faithful classification predictions; however, zeroing in closely on any one part of an image comes at the cost of losing spatial context of the image as a whole, making it harder to localize your classification decision in the process of zooming back out. This is the inherent tension at play in image segmentation tasks, and one that Long et al. work to resolve using skip connections.
In neural networks, a skip connection is a fusion between non-adjacent layers; in this case, skip connections are used to transfer local information by summing feature maps from the downsampling path with feature maps from the upsampling path. Intuitively, this makes sense: with each step we take through the downsampling path of the network, global information gets lost as we zoom into a particular area of the image and the feature maps get coarser, but once we have gone sufficiently deep to make an accurate prediction, we wish to zoom back and localize it, which we can do utilizing information stored in the higher resolution feature maps from the downsampling path of the network. Let’s take a more in depth look at this process by referencing the architecture Long et al. use in their paper:
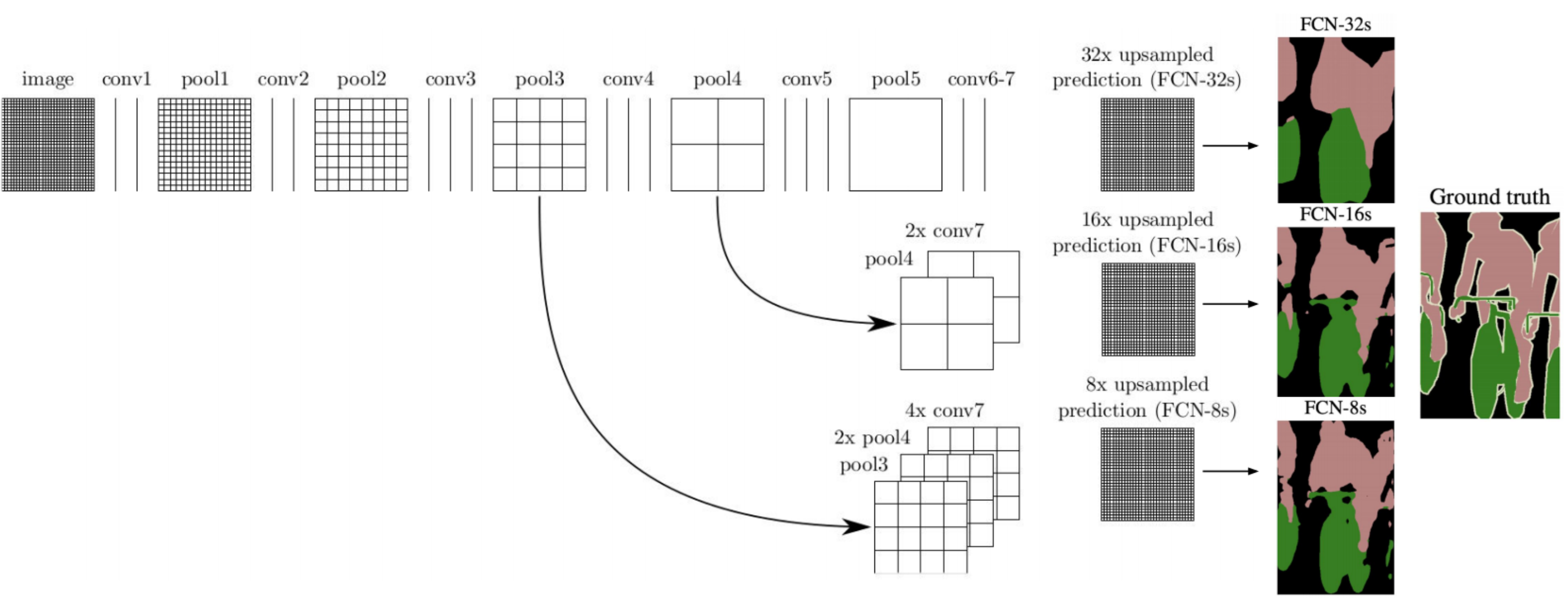
Visualization of skip connections (left arrows) in a network and their effect on the granularity of resulting segmentation maps. Source (modified)
Across the top of the image is the network’s downsampling path, which we can see follows a pattern of two or three convolutions followed by a pooling layer. conv7 represents the coarse feature map generated at the end of the downsampling path, akin to the cat heatmap we saw earlier. The “32x upsampled prediction” is the result of the first architecture without any skip connections, accomplishing all of the necessary upsampling with a single transpose convolutional layer of a 32 pixel stride.
Let’s walk through the “FCN-16s” architecture, which involves one skip connection (see the second row of the diagram). Though it is not visualized, a 1×1 convolution layer is added on top of the “pool4” feature map to produce class predictions for all its pixels. But the network does not end there—it proceeds to downsample by a factor of 2 once more to produce the “conv7” class prediction map. Since the conv7 map is of half the dimensionality of the pool4 map, it is upsampled by a factor of 2 and its predictions are added to those of the pool4, producing a combined prediction map. This result is upsampled via a transpose convolution with a stride of 16 to yield the final “FCN-16s” segmentation map, which we can see achieves better spatial resolution than the FCN-32s map. Thus, although the conv7 predictions experience the same amount of upsampling in the end as in the FCN-32s architecture (given that 2x upsampling followed by 16x upsampling = 32x upsampling), factoring the predictions from the pool4 layer improves the result greatly. This is because pool4 reintroduces valuable spatial information from the input image into the equation—information that otherwise gets lost in the additional downsampling operation for producing conv7. Looking at the diagram, we can see that the “FCN-8s” architecture follows a similar process, but this time a skip connection is also added from the “pool3” layer, which we see yields an even higher fidelity segmentation map.
FCNs—Where to go from here?
FCNs were a big step in semantic segmentation for their ability to factor in both deep, semantic information and fine, appearance information to make accurate predictions via an “encoding and decoding” approach. But the original architecture proposed by Long et al. still falls short of ideal. For one, it results in somewhat poor resolution at segmentation boundaries due to loss of information in the downsampling process. Additionally, overlapping outputs of the transpose convolution operation discussed earlier can cause undesirable checkerboard-like patterns in the segmentation map, which we see an example of below:
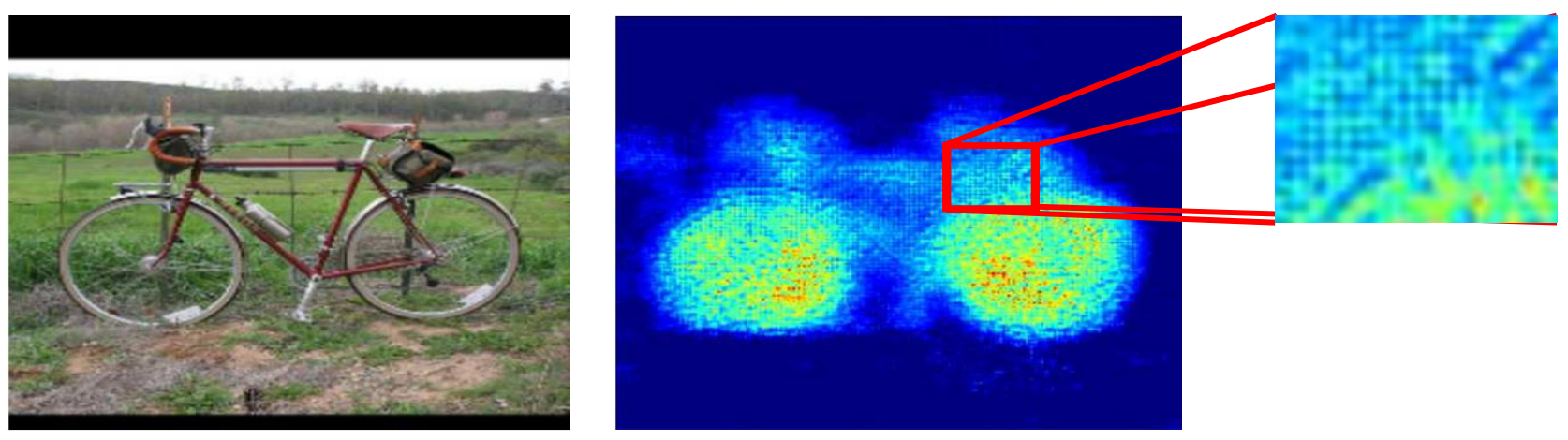
Criss-crossing patterns in a segmentation heatmap resulting from overlapping transpose convolution outputs. Source
Many models have built upon the promising baseline FCN architecture, seeking to iron out its shortcomings, “U-net” being a particularly notable iteration.
U-Net—An Optimized FCN
U-net was first proposed in a 2015 paper as an FCN model for use in biomedical image segmentation. As the paper’s abstract states, “The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization,” yielding a u-shaped architecture that looks like this:
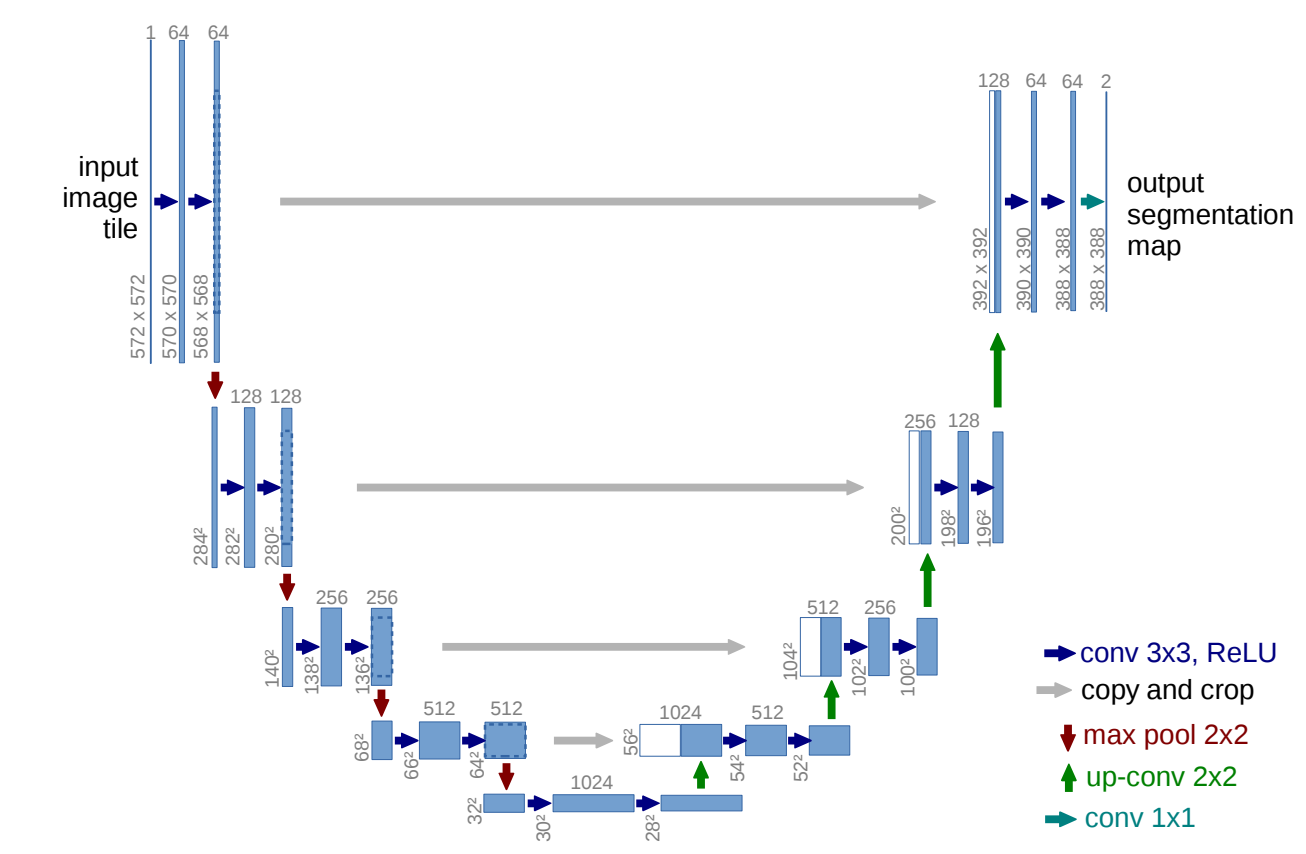
An implementation of the U-net architecture. Numbers at the top of the feature maps denote their number of channels, numbers at the bottom left denote their x-y-size. The white feature maps represent are copies from the downsampling path, which we can see get concatenated to feature maps in the upsampling path. Source
We can see that the network involves 4 skip connections—after each transpose convolution (or “up-conv”) in the upsampling path, the resulting feature map gets concatenated with one from the downsampling path. Additionally, we see that the feature maps in the upsampling path have a larger number of channels than in the baseline FCN architecture for the purpose of passing more context information to higher resolution layers.
U-net also achieves better resolution at segmentation boundaries by pre-computing a pixel-wise weight map for each training instance. The function used to compute the map places higher weights on pixels along segmentation boundaries. These weights are then factored into the training loss function such that boundary pixels are given higher priority for being classified correctly.
We can see that the original U-net architecture yields quite fine-grained results in its cellular segmentation tasks:
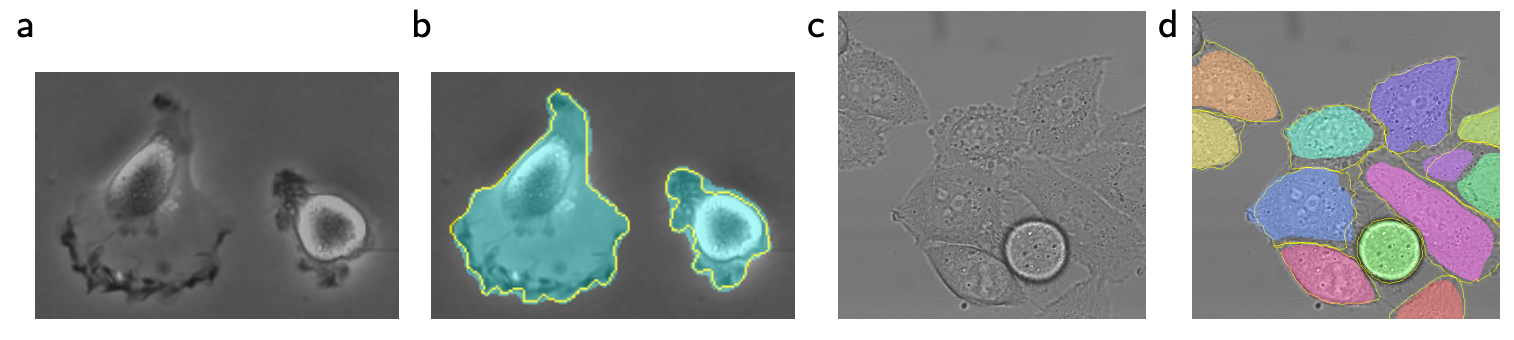
U-net segmentations results in images b and d, with ground truth boundaries outlined in yellow. Source
The development of U-net yet was another milestone in the field of computer vision, and five years later, models continue to expound upon its u-shaped architecture to achieve better and better results. U-net lends itself well to satellite imagery segmentation, which we will circle back to soon in the context of the SpaceNet 6 challenge.
Further Developments in Image Segmentation
We’ve now walked through an evolution of a few basic image segmentation concepts—of course, only scratching the surface of a topic at the center of a vast, rapidly evolving field of research. Here is a list of a few other interesting image segmentation concepts and applications, with links should you wish to explore them further:
- Instance segmentation is a hybrid of object detection and image segmentation in which pixels are not only classified according to the class they belong to, but individual objects within these classes are also extracted, which is useful when it comes to counting objects, for example.
- Techniques for image segmentation extend to video segmentation as well; for example, Google AI uses an “hourglass segmentation network architecture” inspired by U-net for real-time foreground-background separation in YouTube stories.
- Clothing image segmentation has been used to help retailers match catalogue items with physical items in warehouses for more efficient inventory management.
- Segmentation can be applied to 3D volumetric imagery as well, which is particular useful in medical applications; for example, research has been done on using it to monitor the development of brain lesions in stroke patients.
- Many tools and packages have been developed to make image segmentation accessible to people of various skill levels. For instance, here is an example that uses Python’s PixelLib library to achieve 150-class segmentation with just 5 lines of code.
Now, let’s walk through actually implementing a segmentation network ourselves using satellite images and a pre-trained model from the SpaceNet 6 challenge.
The SpaceNet 6 Challenge
The task outlined by the SpaceNet challenge is to use computer vision to automatically extract building footprints from satellite images in the form of vector polygons (as opposed to pixel maps). In the challenge, predictions generated by a model are determined viable or not by calculating their intersection over union with ground truth footprints. The model’s f1 score over all the test images is calculated according to these determinations, serving as the metric for the competition.
The training dataset consists of a mix of mostly synthetic aperture radar (SAR) and a few electro-optical (EO) 0.5m resolution satellite images collected by Capella Space over Rotterdam, the Netherlands. The testing dataset contains only SAR images (for further explanation on SAR imagery, take a look at my last blog). The dataset being structured in this way makes the challenge particularly relevant to real-world applications, as SpaceNet explains, it is meant to “mimic real-world scenarios where historical optical data may be available, but concurrent optical collection with SAR is often not possible due to inconsistent orbits of the sensors, or cloud cover that will render the optical data unusable.”

An example of a SAR image from the SpaceNet 6 dataset, with building footprint annotations shown in red. Source
More information on the dataset, including instructions for downloading it, can be found here. Additionally, SpaceNet released a baseline model, for which they provide explanation and code. Let’s explore the architecture of this model before implementing it to make predictions ourselves.
The Baseline Model
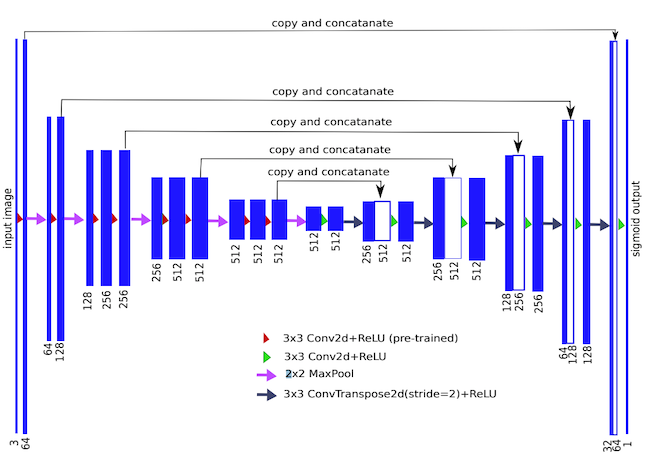
TernausNet architecture. Source
The architecture SpaceNet uses as its baseline is called TernausNet, a variant of U-Net with a VGG11 encoder. VGG is a family of CNNs, VGG11 being one with 11 layers. TernausNet uses a slightly modified version of VGG11 as its encoder (i.e. downsampling path). The network’s upsampling path mirrors its downsampling path, with 5 skip connections linking the two. TernausNet improves upon U-Net’s performance by initializing the network with weights that were pre-trained on Kaggle’s Carvana dataset. Using a model pre-trained on other data can reduce training time and overfitting—an approach known as transfer learning. In fact, SpaceNet’s baseline takes advantage of transfer learning again by first training on only the optical portion of the training dataset, then using the weights it finds through this process as the initial weights in its final training pass on the SAR data.
Even with these applications of transfer learning, though, training the model on roughly 24,000 images is still a very time intensive process. Luckily, SpaceNet provides the weights for the model at its highest scoring epoch, which allow us to get the model up and running fairly easily.
Making Predictions from the Baseline Model
Step-by-step instructions for deploying the baseline model can be found in this blog. In short, the process involves spinning up an AWS Elastic Cloud Compute (EC2) instance to gain access to GPUs for more timely computation and loading the challenge’s Amazon Machine Image (AMI), which is pre-loaded with the software, baseline model and dataset. Keep in mind that the dataset is very large, so downloads may take some time.
Once your downloads are complete, you can find the PyTorch code defining the baseline model in model.py. baseline.py takes care of image preprocessing and running training and testing operations. The weights of the pre-trained model with the best scoring epoch are found in the weights folder and are loaded when test.sh is run.
When we run an image through the model, it outputs a series of coordinates that define the boundaries of the building footprints we are looking to find as well as a mask on which these footprints are plotted. Let’s walk through the process of visualizing an image and its mask side-by-side to get a sense of how effective the baseline model is at extracting building footprints. Code for producing the following visualizations can be found here.
Getting a coherent visual representation of the SAR data is somewhat trickier than expected. This is because each pixel in a given image is assigned 4 values, corresponding to 4 polarizations of data in the X-band of the electromagnetic spectrum—HH, HV, VH and VV. In short, signals transmitted and received from a SAR sensor come in both horizontal and vertical polarization states, so each channel corresponds to a different combination of the transmitted and received signal types. These 4 channels don’t translate to the 3 RGB channels we expect for rendering a typical image. Here’s what it looks like when we select the channels one-by-one and visualize them in grayscale:

Visual representations of the 4 polarizations of a single SAR image. Image by author
Notice that each of the 4 polarizations captures a slightly different representation of the same area of land. We can combine these representations to produce a single-channel span image to plot alongside the building footprint mask the model generated, which we convert to binary to make the boundaries more clear. With this, we can see that the baseline model did recognize the general shapes of several buildings:
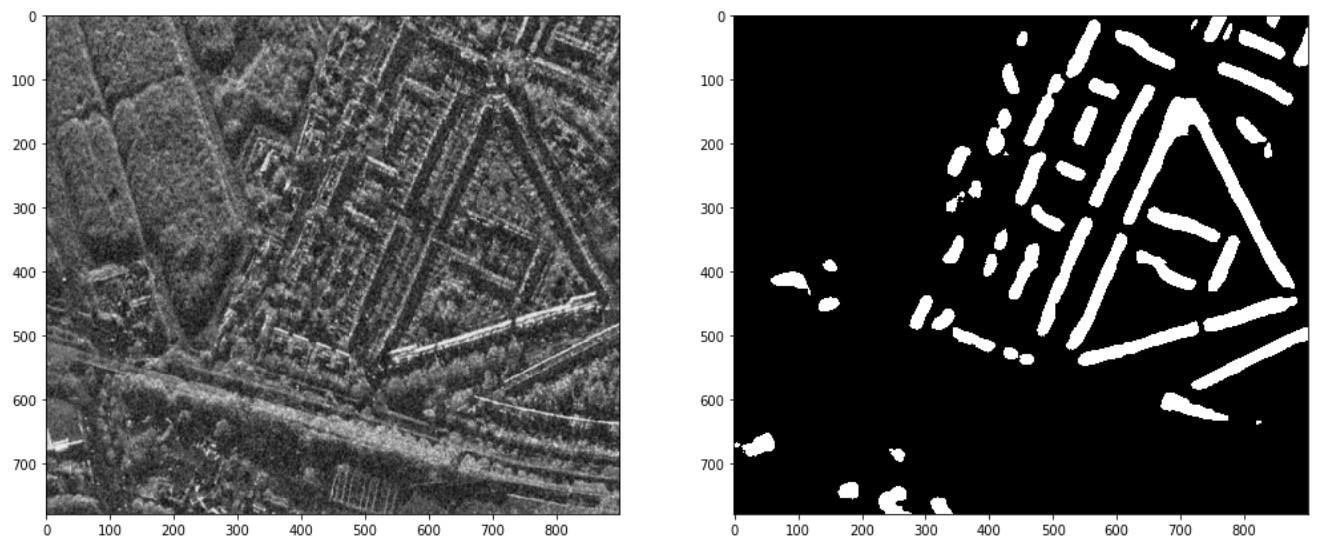
A visualization of the combined spectral bands of a SAR test image and the corresponding building footprint mask generated by the baseline model. Image by author
It is pretty cool to see the basic structures we’ve discussed in this post in action here, producing viable image segmentation results. But, it’s also clear that there is room for improvement upon this baseline architecture—indeed, it only achieves an f1 score of 0.21 on the test set.
Conclusion
The SpaceNet 6 challenge wrapped up in May, with the winning submission achieving an f1 score of 0.42—double that of the baseline model. More details on the outcomes of the challenge can be found here. Notably, all of the top 5 submissions implemented some variant of U-Net, an architecture that we now have a decent understanding of. SpaceNet will be releasing these highest performing models on GitHub in the near future and I look forward to trying them out on time series data to do some exploration with change detection in a future post.
Lastly, I’m very thankful for the thorough and timely assistance I received from Capella Space for writing this—their insight into the intricacies of SAR data as well as recommendations and code for processing it were integral to this post.
References
- https://missinglink.ai/guides/computer-vision/image-segmentation-deep-learning-methods-applications/
- https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
- https://engineering.matterport.com/splash-of-color-instance-segmentation-with-mask-r-cnn-and-tensorflow-7c761e238b46
- https://arxiv.org/abs/1411.4038
- https://www.youtube.com/watch?v=nDPWywWRIRo&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=11
- http://deeplearning.net/tutorial/fcn_2D_segm.html
- https://www.topbots.com/semantic-segmentation-guide/
- https://arxiv.org/pdf/1505.04597.pdf
- https://medium.com/the-downlinq/spacenet-6-announcing-the-winners-df817712b515
- https://simularity.com/using-aisaroptical-to-find-the-invisible/

LIDAR plays a major role in automotive, as vehicles perform tasks with less and less human supervision and intervention. As a leader in VCSEL, ams is helping to shape this revolution.
LIDAR (Light Detection and Ranging) is an optical sensing technology that measures the distance to other objects. It is currently known for many diverse applications in industrial, surveying, and aerospace, but is a true enabler for autonomous driving. As the automotive manufacturers continue their push to design and release high-complexity autonomous systems, we likewise develop the technology that will enable this. That is why ams continues to bring our high-power VCSELs to the automotive market and to test the limits on peak power, shorter pulses, and additional scanning features which enable our customers to improve their LIDAR systems.
In 2019, ams together with ZF and Ibeo announced a hybrid solution called True Solid State where, like flash technology, no moving parts are needed to capture the full scene around the vehicle. By sequentially powering a portion of the laser, a scanning pattern can be generated, combining the advantages of flash and scan systems.
Making sense of the LIDAR landscape
At ams, we classify LIDAR systems on seven elements: ranging principle, wavelength, beam steering principle, emitter technology and layout, and receiver technology and layout. Here we discuss the first five.
The most dominant implementation to measure distance (ranging) is Direct Time of Flight (DTOF): a short (few nanoseconds) laser pulse is emitted, reflected by an object and returned to a receiver. The time difference between sending and receiving can be converted into a distance measurement. Moreover, with duty cycles of <1% this system takes thousands of distance measurements per second. The laser pulse is typically in the 850-940nm rage, components are readily available and most affordable. However, systems can also be using 1300 or 1550nm, the big advantage is eye safety regulations allow more energy to be used here, and in theory, this provides more range. The downside is that components are expensive.
To scan the complete surroundings (or field of view) of a vehicle, the system needs to be able to shoot pulses in all directions. This is the beam steering principle. Classical systems used rotating sensor heads and mirrors to scan the field of view section by section. As these systems are bulky, they are being replaced by static systems with internal moving mirrors. MEMS mirrors are also about to enter the market. Another approach is flash, where no moving parts are needed at all. The light source illuminates the complete field of view, and the sensor captures that same field in a single frame like a photo. As the full scene is illuminated, and to remain eye safe, this means the range must be limited.
On the emitter side, edge emitters continue to be frequently used, based on earlier developments. They have a high-power density, making them suitable in combination with MEMS mirrors. Where first iterations were single emitters, meanwhile 2-4-8-16 emitters are being integrated in a single bar. Fiber lasers are another interesting technology. They offer even higher power density, and typically are used in 1550nm wavelength and come typically as a single emitter source.
ams is a leading supplier in the VCSEL emitter technology. Our high power VCSELs can differentiate in scan and flash applications as they are very stable over temperature, are less sensitive to individual emitter failures, and are easy to integrate. However, the best characteristic of VCSELs are their ability to form emitter arrays. This makes VCSELs easy to scale. It also allows for addressability, or powering selective zones of the die. This enables True Solid State topology, which we consider to be the most all-rounded LIDAR solution.

LIDAR enables Autonomous Driving
The most commonly accepted way to classify vehicles on their level of autonomy is by the definitions of the Society of Automotive Engineers (SAE). At SAE Level 3 and above, the vehicle takes over responsibility from the driver and assistance turns into autonomy. This means the vehicle should be able to perform its task without human supervision and intervention. This requires a step function in required system performance. Where Level 1 and Level 2 vehicles assist the driver and typically rely on camera or radar, or a combination, there are shortcomings in these technologies for 3D object detection. LIDAR technology addresses this, and there is wide consensus in the industry that from Level 3 onwards, LIDAR is needed for 3D object detection.
When 3D LIDAR is combined or fused with camera and radar, a high-resolution map of the vehicle’s surroundings can be constructed and allow the vehicle to safely fulfil its mission. The automotive industry started with more straightforward driver-assist use cases used in Level 1 and Level 2. As sensors and data processing gets more advanced, further more difficult use cases can be covered, such as Highway Pilot or City Pilot.
Ultimately, when every conceivable use case can be fulfilled by the system we define this as a Level 5 vehicle – fully autonomous and the holy grail of autonomous driving. This is expected to still be quite a number of years out from today. Moreover, there will be huge pressure to bring down cost and rationalize content per vehicle – to make autonomous driving available to the mass market.
Interested to learn more?
Let us know if you would like to discuss how you could be using ams technology to support your potential LIDAR applications!
Contact ams sensor experts

5G is no longer just a promise—it’s very real, even though implementation is in its infancy. There are two examples from 2019 that demonstrate that 5G implementations are materializing. One is that Verizon launched 5G service in all its NFL football stadiums. The other example is that in South Korea, 5G subscribers reached more than 2 million by August of that year – just four months after local carriers commercially launched the technology. In this post, we explore what’s advancing 5G in these areas such as small cell densification, spectrum gathering, spectrum sharing and massive MIMO. Although it will take time to become ubiquitous, 5G is expected to be the fastest-growing mobile technology ever. According to the Global Mobile Supplier Association (GSA), 5G is expanding at a much faster pace than 4G LTE—approximately two years faster. GSA recently published data stating that more than 50 operators launched 5G mobile networks and at least 60 different 5G mobile devices are available across the world.
Ultimately, 5G will have a life-changing impact and transform many industries. However, for 2020, operators are focusing on supporting the first two major 5G use cases: faster mobile connectivity and fixed wireless access (FWA), which brings high-speed wireless connectivity.
The rapid pace of 5G development is highlighted in the 2nd edition of Qorvo’s 5G RF For Dummies book. This NEWLY UPDATED book describes key trends and technology enablers that are bringing 5G visions to life.
Here are some highlights in the book:
- Network Densification and Small Cells
5G users will require more cell sites to greatly expand network capacity and support the increase in data traffic. This is prompting mobile network operators (MNOs) to rush and densify their networks using small cells—which are small, low-powered base stations installed on buildings, attached to lamp posts, and in dense city venues. These small cells will help MNOs satisfy the data-hungry users, improving quality-of-service.
- Spectrum Gathering
5G requires vast amounts of bandwidth. More bandwidth enables operators to add capacity and increase data rates so users can download big files much faster and get jitter-free streaming in high resolution. The physical layer and higher layer designs are frequency agnostic, but separate radio performance requirements are specified for each. The lower frequency range (FR1), also called sub-7 GHz, runs from 410 to 7,125 MHz. The higher frequency range (FR2), also called millimeter Wave (mmWave), runs from 24.25 to 52.6 GHz.

5G RF For Dummies, Second Edition
Download and read this NEW UPDATED VERSION of our 5G RF For Dummies Book
To obtain the bandwidth in FR1 and FR2, more spectrum must be allocated. Already, regulators in roughly 40 countries have allocated new frequencies and enabled re-farming of LTE spectrum. However, much more will be needed. To provide at least some of that, 54 countries plan to allocate more spectrum between now and the end of 2022, according to the GSA.
- 4G to 5G Network Progression
5G Radio Access Network (RAN) is designed to work with existing 4G LTE networks. 3GPP allowed for multiple New Radio (NR) deployment options. Thus, making it easier for MNOs to migrate to 5G by way of a Non-Standalone (NSA) to Standalone (SA) option, as shown in the figure below.

- Dynamic Spectrum Sharing
Dynamic spectrum sharing (DSS) is a new technology that can further help smooth the migration from 4G to 5G. With DSS, operators can allow 4G and 5G users to share the same spectrum, instead of having to dedicate each slice of spectrum to either 4G or 5G. This means operators can use their networks more efficiently and optimize the user experience by allocating capacity based on users’ needs. Thus, as the number of 5G users increases, the network can dynamically allocate more of the total capacity to each user.
- Millimeter Wave (mmWave)
5G networks can deliver the highest data rates by using mmWave FR2 spectrum, where large expanses of bandwidth are available. mmWave is now a reality: 5G networks are using it for FWA and mobile devices and will apply it for other use cases in the future. Operators expect to roll out FWA to more homes, as 5G network deployment expands and suitable home equipment becomes available.
- Massive MIMO
MIMO (multiple-input and multiple-output) increases data speeds and network capacity by employing multiple antennas to deliver several data streams using the same bandwidth. Many of today’s LTE base stations already use up to 8 antennas to transmit data, but 5G introduces massive MIMO, which uses 32 or 64 antennas and perhaps even more in the future. Massive MIMO is particularly important for mmWave because the multiple antennas focus the transmit and receive signals to increase data rates and compensate for the propagation losses at high frequencies. This brings huge improvements in throughput and energy efficiency.
- RFFE Innovations that Enable 5G
Innovation in RF front-end (RFFE) technologies are needed to truly enable the vision of 5G. As handsets, base stations and other devices become sleeker and smaller, the RFFE will need to pack more performance into less space while becoming more energy-efficient. Some RF technologies are key in achieving these goals for 5G. They include:
- Gallium Nitride (GaN). GaN is well suited for high-power transistors capable of operating at high temperatures. The potential of GaN PAs in 5G is only beginning to be realized. Their high RF power, low DC power consumption, small form factor, and high reliability enable equipment manufacturers to make base stations that are smaller and lighter in weight. By using GaN PAs, operators can achieve the high effective isotropic radiated power (EIRP) output specifications for mmWave transmissions with fewer antenna array elements and lower power consumption. This results in lighter-weight systems that are less expensive to install.
- BAW Filters. The big increase in the number of bands and carrier aggregation (CA) combinations used for 5G, combined with the need to coexist with many other wireless standards, means that high-performance filters are essential to avoid interference. With their small footprint, excellent performance, and affordability, surface acoustic wave (SAW) and bulk acoustic wave (BAW) filters are the primary types of filters used in 5G mobile devices.
-Blog from https://www.qorvo.com/
Author – David Schnaufer
Technical Marketing Communications Manager